1. Introduction
An increase in sea level will considerably impact the low-lying coastal regions and increase the risk of floods [
1,
2,
3,
4]. In Malaysia, the low-lying coastal regions host very large cities and are densely populated. Therefore, the future increase in sea level should be comprehensively analyzed to protect the low-lying residential regions and coastal areas [
5,
6,
7,
8,
9].
Various methods have been introduced for predicting the sea level increase [
10,
11]. These methods have been developed based on the simple linear production process. Therefore, these methods failed to capture the nonlinearity and complexity associated with the systems [
12,
13,
14,
15].
The selection of the appropriate model input considerably influences the model accuracy. The accuracy of the current models used to predict the increase in sea level differs in terms of the prediction horizons (1, 5, 10, 20, and 40 years). Various parameters (rainfall, sea surface temperature, etc.) should be incorporated into these models to improve their performances and successfully reduce the magnitude of uncertainty and prediction error. However, most of these meteorological data are often unavailable [
16].
The artificial intelligence techniques have recently gained considerable attention from researchers and have been implemented to overcome the limitations associated with the current models. These techniques have become some of the favorable computational methods for predicting the increase in sea level because they can achieve fast computation using only a few parameters as the input [
17,
18,
19,
20]. Support vector machines (SVMs) have recently attracted the interest of many researchers for different prediction scenarios [
21,
22]. Asefa et al. [
23] successfully used the SVM for the prediction of the Sevier River Basin (South-Central Utah, USA) at hourly and seasonal intervals. Lu and Zhang (2006) [
24] denoted that the SVM outperformed the ANN) during the prediction of annual runoff. Li et al. (2008) [
11] combined the SVM with chaos analysis to predict the runoff. The SVM model uses a sigmoid kernel function that enables the model to solve a quadratic programming problem with linear constraints instead of solving a nonconvex and unconstrained minimization problem similar to that in standard ANN training [
24]. Pochwat and Daniel (2018) [
25] analyzed the application feasibility of ANNs for the preliminary estimation of the duration of critical rainfalls. The results obtained using the ANN can be applied in the simplified method used for directly estimating the reliable rainfall duration.
Genetic programming (GP) is a type of evolutionary computational (EC) method, which is a subset of machine learning used to discover solutions to problems that humans have failed to directly solve [
26].
Further, the EC techniques can solve difficult problems associated with several different domains, particularly human-competitive machine intelligence [
27]. Koza, the father of GP [
28], successfully proved the liability of symbolic regression with GP. Optimization is an important subject exhibiting several important applications, and various optimization algorithms have been successfully used for a wide range of applications [
29,
30]. The most frequently used optimization algorithms include modern metaheuristics, which have introduced a new branch of optimization that can be referred to as metaheuristic optimization.
In GP, a metaheuristic is a condition in which an algorithm is designed for inductive automatic programming and is very suitable for performing the symbolic regression and machine learning tasks. Previous studies have proved that GP can be used as a time series prediction method in various fields. Ghorbani et al. (2010) [
31] used GP for forecasting the sea water level at Hillarys Boat Harbor in Western Australia and showed that GP can simulate nonlinear forecasting. The standalone results were then compared with those of the ANN standalone. Consequently, the former was found to perform marginally better for majority of the results. Yan et al. (2019) [
32] proposed a hybrid optimized algorithm involving particle swarm optimization (PSO) and genetic algorithm (GA) combined with a BP neural network that can predict the water quality in time series and exhibited a good performance in the Beihai Lake in Beijing. Their study results denoted that the model based on PSO and GA that optimized the BP neural network can predict the water quality parameters with a reasonable accuracy, suggesting that this model is valuable for estimating the quality of lake water. Jonathan and Hatim (2016) [
33] focused on modeling the rainfall–runoff relation in a mid-size catchment. As a standalone application, GP was able to outperform the published ANN results obtained using the same dataset, resulting in an average absolute relative error of 17.118 and a Nash–Sutcliffe (
E) of 0.937.
The shoreline at the east coast of Peninsular Malaysia (ECPM) is susceptible to direct impacts from severe storms, especially during the northeast monsoon periods. Furthermore, ECPM has a well-established oil refinery offshore structure, a power plant near the shore, and a well-known island with a tourism population. Thus, the increase in sea level rise should be studied to minimize its impact toward these resources at the ECPM.
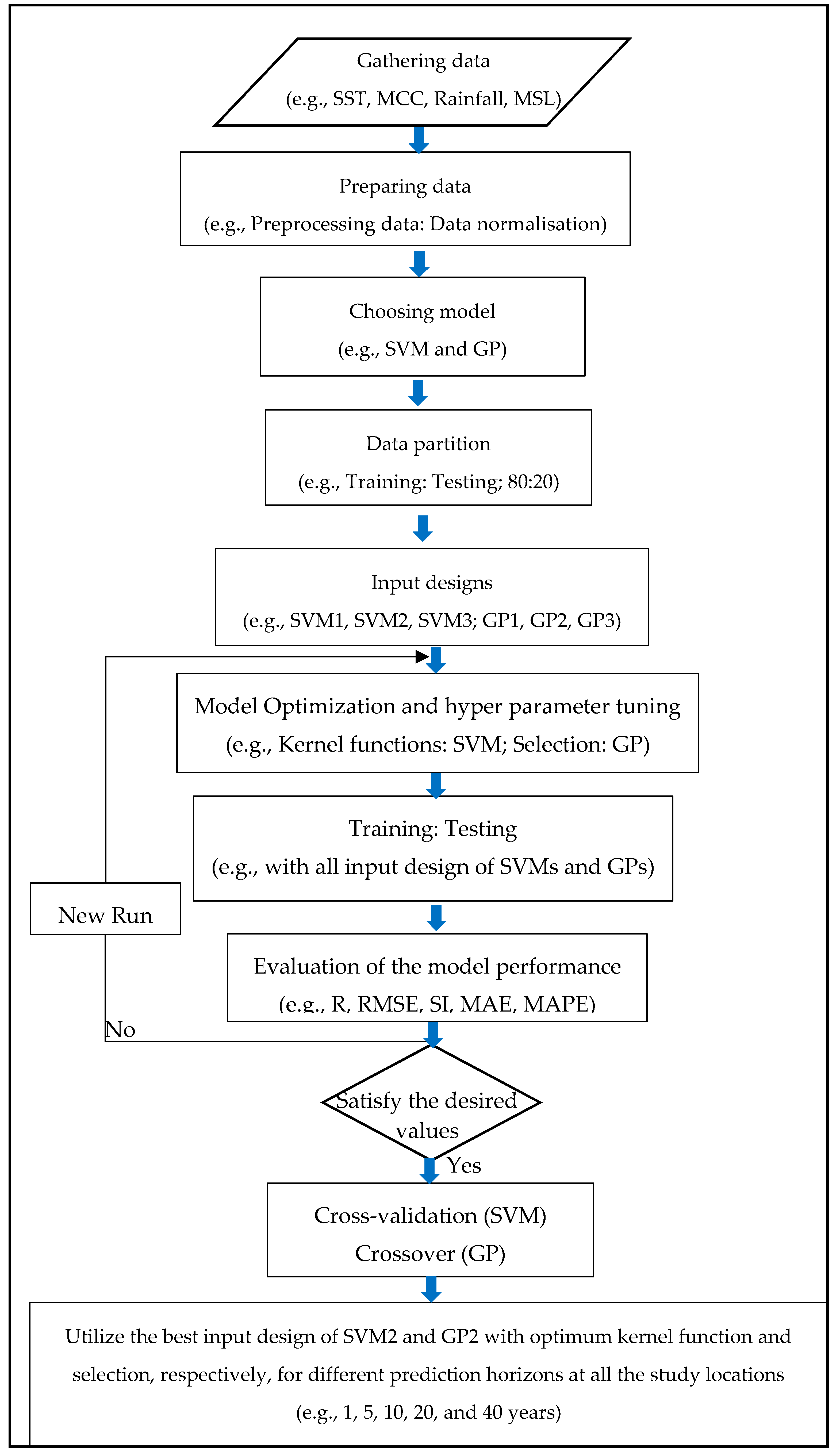
This study implemented two models—SVM and GP—with six different input design parameters. The input design parameters exhibiting a high correlation coefficient were selected for the monthly mean sea level prediction in this study and at two other study locations. Both the model performances were subsequently compared to evaluate their robustness. The highest correlation function kernel and selection of the most optimal input design were executed in different prediction horizons (i.e., 1, 5, 10, 20, and 40 years) [
31,
32,
33] using the two proposed methods.
3. Results
This study aimed to examine the capability of the SVM and GP models in different prediction horizons of 1, 5, 10, 20, and 40 years for MMSL forecasting of the sea level in Kerteh, the Tioman Island, and Tanjung Sedili at the EPCM. The results of the study using the SVM in various kernel functions (i.e., NP, RBF, and PUK) and in the GP-based model, namely the ramped half–half (RHH) model with fitness-proportional selection and rank selection, were obtained for comparing the capabilities of the two models.
SVM and GP among different input designs (i.e., SVM1, SVM2, and SVM3 and GP1, GP2, and GP3) were executed to determine the correlation between the input and output of the models by examining the prediction accuracy in terms of the statistical model performance. The input designs of the SVM (SVM1, SVM2, and SVM3) and GP (GP1, GP2, and GP3) were then optimized using different kernel functions of NP, RBF, PUK, and RHH with rank or fitness selection to find the most optimal tuning or affecting parameters for further predicting the horizons.
3.1. Model Performances of the SVM Model
As summarized in
Table 3 for Kerteh, for the SVM1 input design based on the combination of the MSL and the SST, the RBF kernel showed an average performance with correlation coefficients of 0.510 and 0.443 for training and testing, respectively. The NP and PUK kernels in SVM1 were not able to perform. In addition, the input designs of SVM3 at Kerteh showed that among the three different kernels, a slight decrease in accuracy was observed in terms of R and RMSE when compared with that observed in the NP and PUK kernels in SVM2. However, R managed to become greater than 0.7 during training. Meanwhile, PUK performed slightly better than NP during testing. However, the RBF performance for the SVM3 input design plummeted when compared with that of SVM2. The model performance was unable to reach a moderate accuracy of R = 0.5 during the testing stage. Furthermore, the SVM2 input design at Kerteh depicted a significant increase in model performance in terms of R, RMSE, SI, MAE, and MAPE. The comparison between the NP and the RBF for the SVM2 input design showed that the NP outperformed the RBF. However, the PUK kernel performed better than the NP kernel.
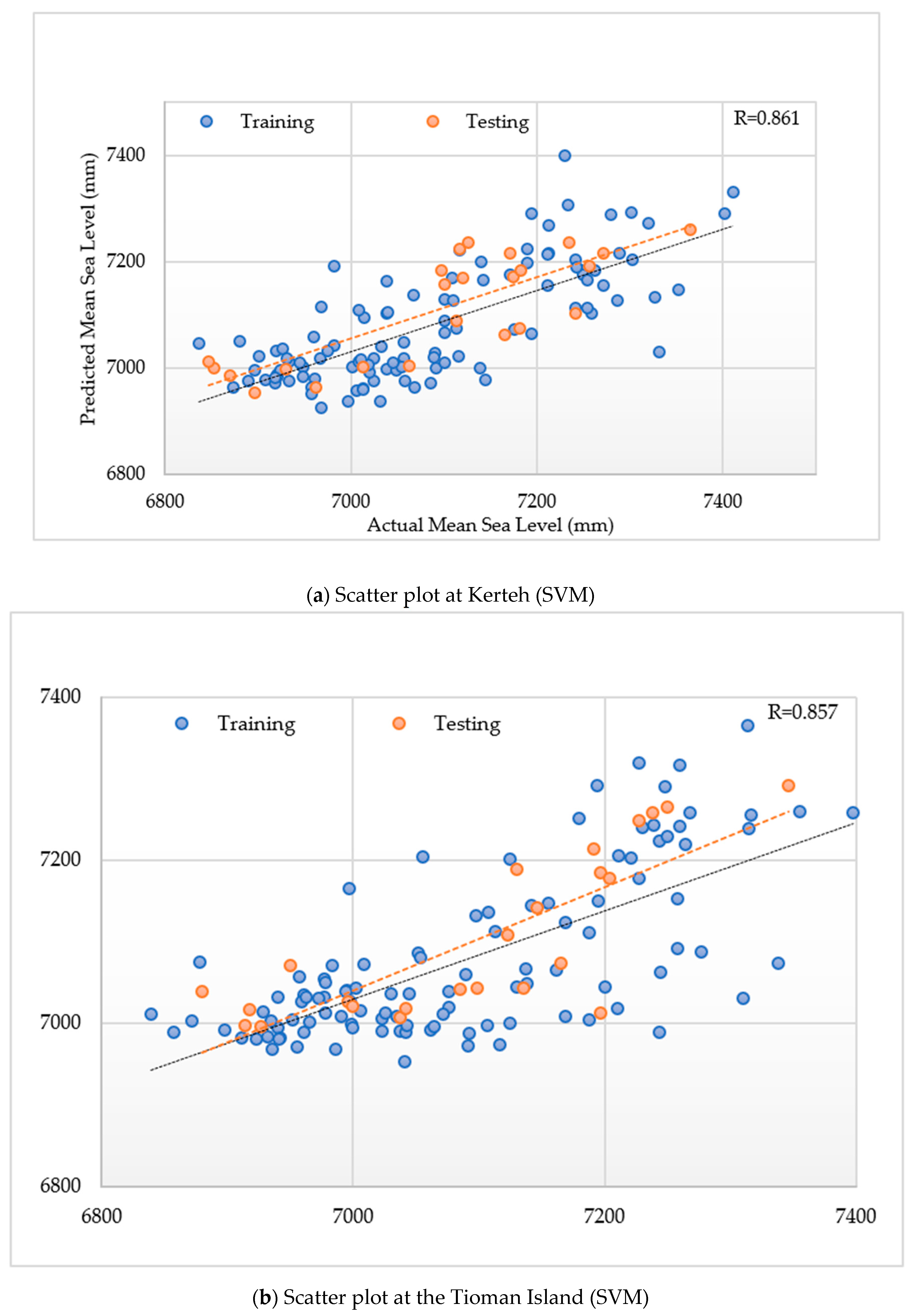
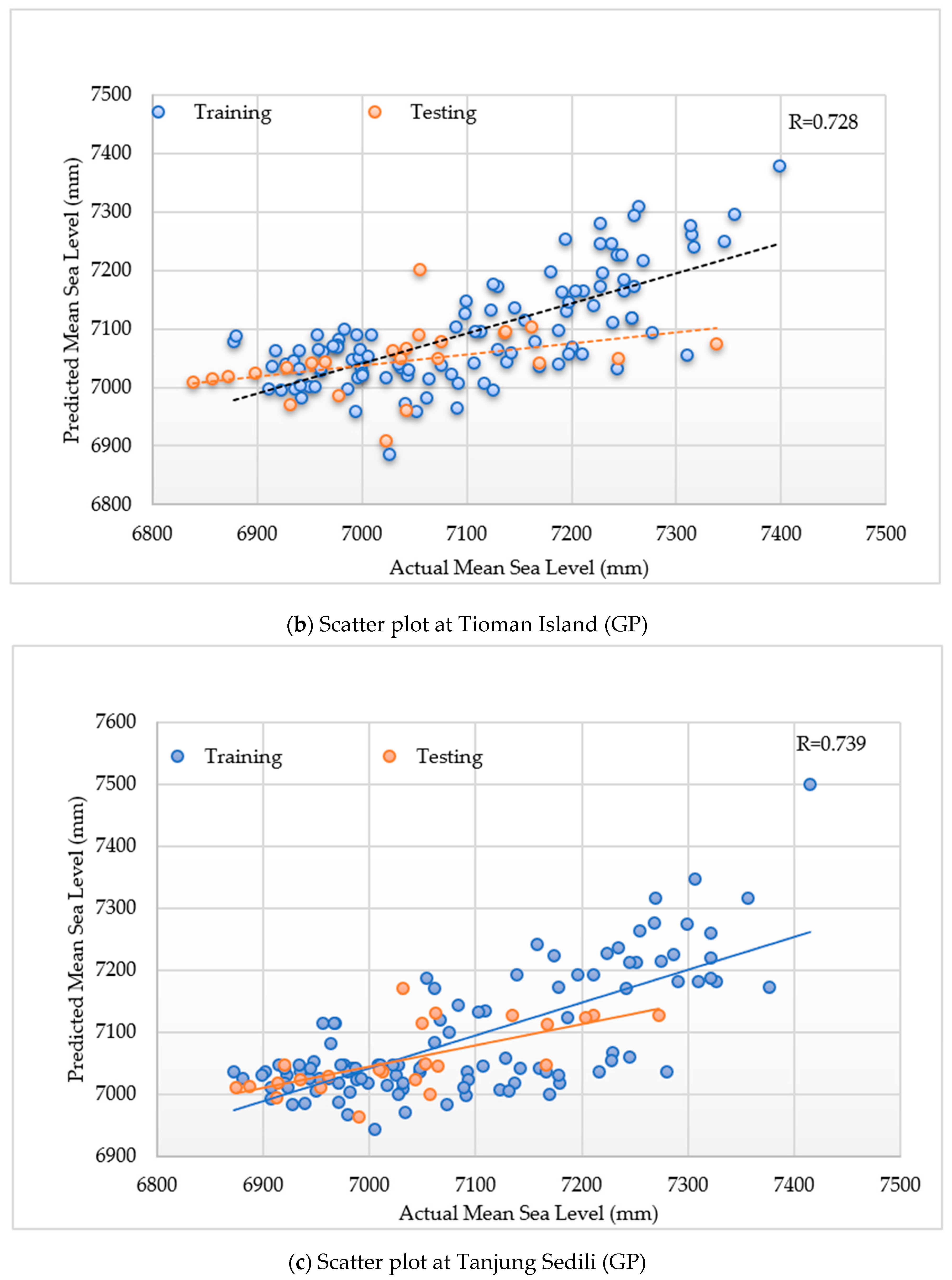
Figure 5a–c present the scatterplots of the actual versus predicted sea levels. The PUK model was capable of precisely mimicking the actual data during the training and testing stages for a 10-year horizon when compared with the remaining different kernels. Hence, the implementation of the PUK function for the proposed SVM models can improve the accuracy. Furthermore, it can be introduced as a perfect substitute model for predicting increases in sea level that are usually nonlinear at several locations along the shoreline.
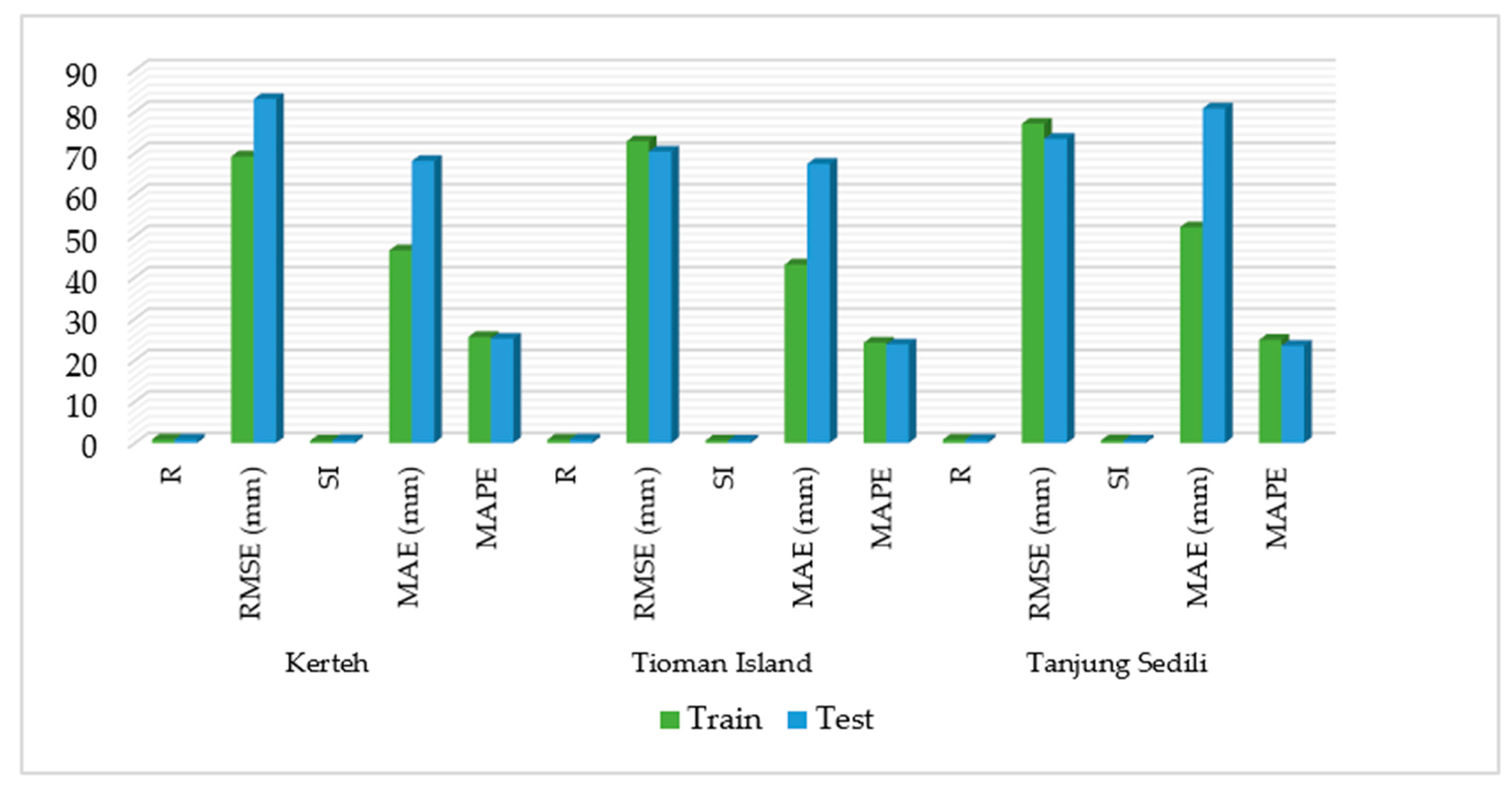
Figure 6 depicts the results in which the PUK fairly accurately performed at three different locations.
The results of the PUK with the SVM2 input design at Kerteh was outperformed other kernel functions. Thus, the Tioman Island and Tanjung Sedili were generalized using the PUK with the SVM2 input design.
Figure 6 presents the model performances of the R, RMSE, SI, MAE, and MAPE at Kerteh, the Tioman Island, and Tanjung Sedili. The best R performance was 0.820 and 0.857 for the training and testing periods, respectively, at the Tioman Island, whereas the optimal PUK model was observed to be that with minimum RMSE values of 72.83 and 70.34 mm during the training and testing periods, respectively.
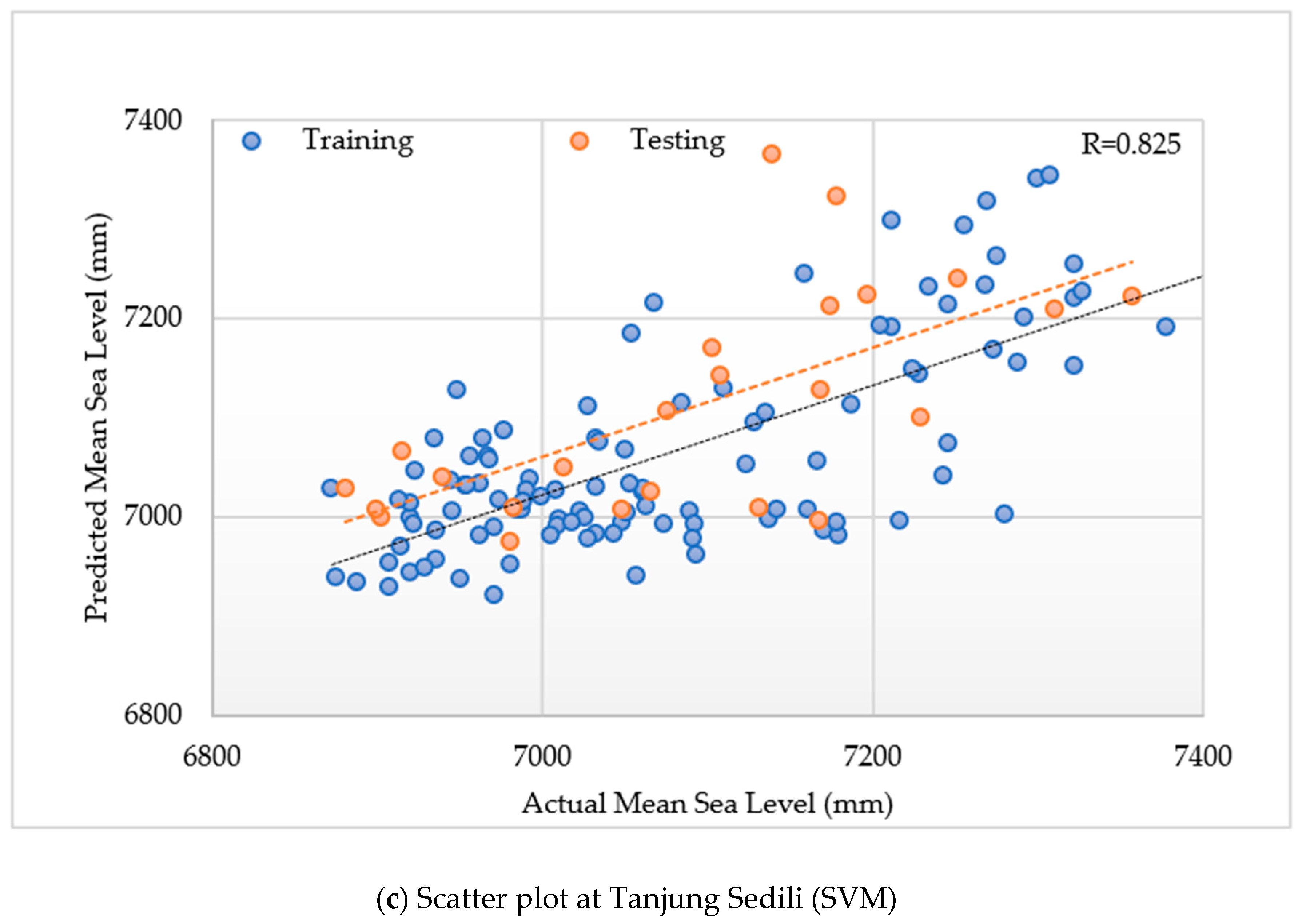
In accordance with
Figure 6, the PUK was optimal with R of 0.815 and 0.825 for training and testing, respectively, at Tanjung Sedili. The optimal PUK model was clearly the one showing minimum RMSE values of 77.1 and 73.43 mm during the training and testing periods, respectively (
Figure 6).
In addition, the model performances of SI for the Tioman Island were 0.61 and 0.58 during the training and testing periods, respectively, whereas those for Tanjung Sedili were 0.64 and 0.611 during the training and testing periods, respectively.
Figure 6 illustrates that the MAE at the Tioman Island is 43.08 and 67.41 mm during the training and testing periods, respectively, and that the MAPE is 24.2% and 23.8% during the training and testing periods, respectively. The MAE at Tanjung Sedili decreased to 52.08 and 80.76 mm during the training and testing periods, respectively. Meanwhile, the MAPE at Tanjung Sedili was 24.9% and 23.5% during the training and testing periods, respectively.
3.2. Optimal Kernel Functions with the Input Design of SVM2 for the Cross-Validation Process
The results for majority of the optimal tuning or affecting parameter settings were obtained in the best kernel function, the PUK with the SVM2 input design for the cross-validation techniques (
Table 4). The dataset was divided into two subsets; one subset was assigned to train the models, whereas the other was used to evaluate the performance of the best models.
3.3. Model Performances of GP
The model performances were executed using the input design of GP1 Equation (7). The combination of the MSL and SST could not achieve the best performance in terms of RHH and rank selection because of the lack of accuracy obtained during the testing stage. However, RHH and fitness selection attained a model performance similar to that of GP3. However, both GP1 and GP3 only worked for an alternative purpose, and the optimal model performance from the input design of GP2 was still more convincing.
The input design of GP2 with RHH and fitness selection outperformed the results when compared with the results of half–half and rank selection that exhibited inconsistency of performance during the testing stage with R = 0.45. However, the training results provided a convincible value of R = 0.78 in
Figure 6. RHH and fitness selection had the best model performance run in GP2 because of these unstable model selections. Moreover, the optimal RHH with the fitness-proportional selection model had a minimum RMSE value of 89.20 mm during the testing period.
The input design of GP3 for the RHH and fitness functions obtained persuasive model performance results because the combination of the input design of GP3 did not have rainfall input; however, the training and testing stages yielded correlation coefficients of 0.756 and 0.57, respectively, which are considered as above-average and acceptable outcomes if no rainfall data are used as input parameters. The advantage of this combination of GP3 may benefit the impromptu prediction required for coastal management because the model performance did not show a value lower than R = 0.5. Hence, this combination can be an alternative method for predicting the SL.
Table 5 presents the summary of the model performances of the GP with different selections and input designs executed at Kerteh. The model performance was evaluated in terms of R, RMSE, SI, MAE, and MAPE. Throughout the model among the three input designs, the best model performance was obtained from GP2 with RHH and fitness-proportional selection. Hence, the performances of GP2 with RHH and fitness-proportional selection were executed at the Tioman Island and Tanjung Sedili.
In case of the Tioman Island, the input design of GP2 with RHH and fitness-proportional selection showed R values of 0.712 and 0.728 for the training and testing periods, respectively (
Figure 7). Meanwhile, at Tanjung Sedili, the R values were 0.793 and 0.739 for the training and testing periods, respectively.
The input design at Kerteh was outperformed by the RHH and the fitness-proportional selection with GP2. Thus, the Tioman Island and Tanjung Sedili were generalized with the RHH and the fitness-proportional selection with GP2.
Figure 8 shows that the RMSE at the Tioman Island was 90.46 and 84.88 mm during the training and testing periods, respectively, whereas that at Tanjung Sedili was 86.52 and 79.32 mm during the training and testing periods, respectively.
The model performance of SI for the Tioman Island yielded 1.25 and 1.01 for the training and testing periods, respectively, whereas that at Tanjung Sedili yielded 1.29 and 1.05 for the training and testing periods, respectively.
Figure 8 also illustrates that the MAE at the Tioman Island was 101.3 and 97.4 mm for the training and testing periods, respectively, and that the MAPE was 28.2% and 25.4% for the training and testing periods, respectively. The MAE at Tanjung Sedili was 101.5 and 111.2 mm, respectively, and the MAPE was 25.2% and 26.1% for the training and testing periods, respectively.
3.4. Optimal Selection Function with the Input Design of GP2 in the Crossover Process
The crossover operation frequency can be determined by the crossover rate in GP [
44]. It is advisable to search for a promising region at the beginning of optimization. The convergence speed decreases with low crossover frequencies. The mutation operation is restrained by the mutation rate. A high population diversity introduced by a high mutation rate may lead to instability. A typical choice of setting the initial GP control parameters would involve the generation run (termination criterion) being fixed at 300 runs to obtain the optimal results and the population being fixed at 500 [
42]. These control parameters were managed to match the input data design, and the capability of the model was good (
Table 6).
3.5. Comparison of the Average Error Percentages in SVM2 and GP2 at the Study Locations
Figure 9 illustrates a comparison of the SVM2 and GP2 average error percentages of both models at Kerteh, the Tioman Island, and Tanjung Sedili.
Figure 8 demonstrates the fluctuation trendline for both the error percentages obtained from SVM2 and GP2 starting from January 2007 to December 2017.
The highest average percentage error for SVM2 was 1.61% in 2007 and occurred at the Tioman Island. However, the highest average percentage error for GP2 was 1.32% in 2013 and 2016, which could be observed at Tanjung Sedili and the Tioman Island, respectively. The average error percentages of both the models were not higher than 5%.
Figure 9 presents the lowest average percentage error belonging to the SVM2 model of 0.61%–0.64% in 2008, 2014, and 2016, which occurred at the Tioman Island and Kerteh. The lowest average percentage error for the GP2 was 0.72–0.81% in 2009, 2011, and 2012 and occurred at Kerteh.
Figure 9 also illustrates that both the model performances did not show an average percentage error of more than 5%. Thus, these models can be used as the prediction models for the MSL.
The comparison of SVM2 and GP2 with the most optimal kernel functions was evaluated using the AI equation (
Figure 8).
3.6. Comparison of the Accuracy Improvement (AI) in SVM2 and GP2 at the Study Locations
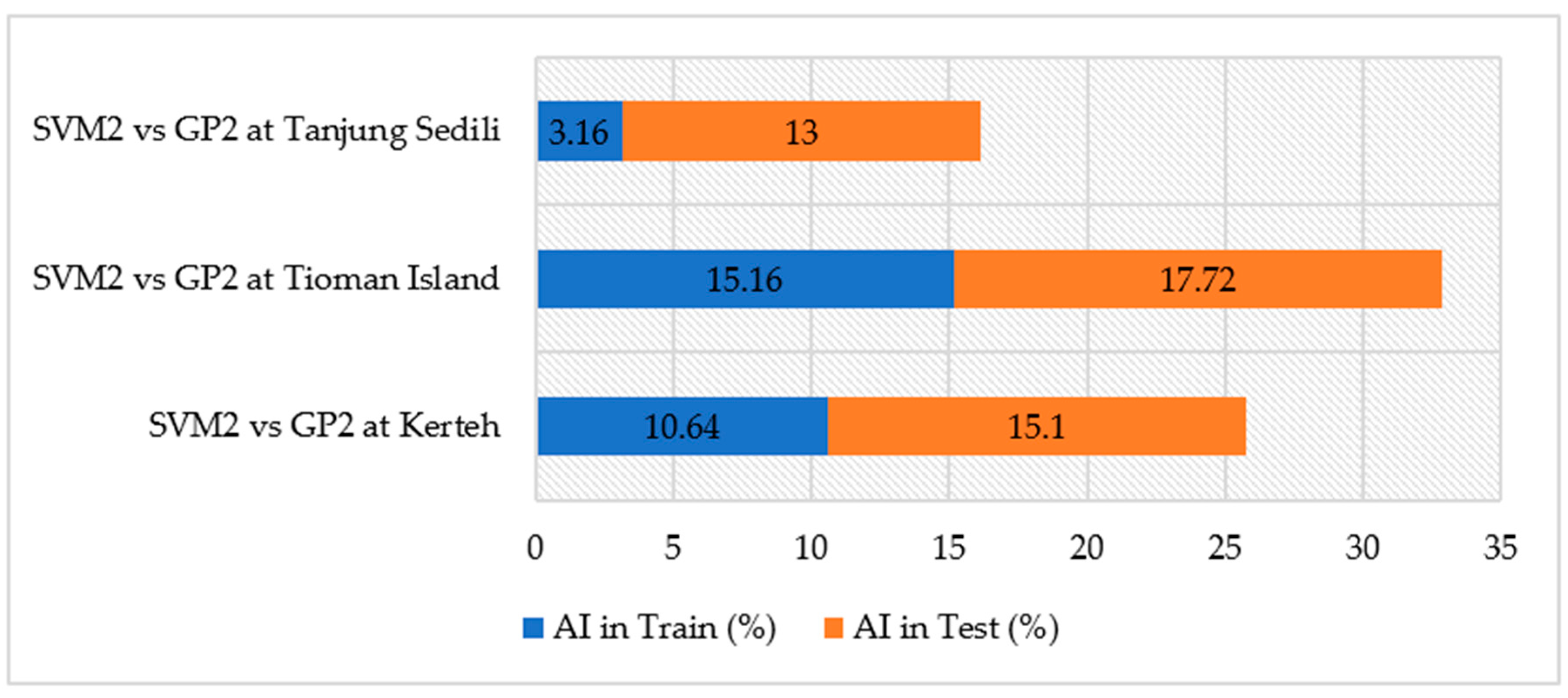
Figure 10 represents the accuracy improvement percentages of SVM2 and GP2 at Kerteh with values of 10.64% and 15.1% during the training and testing stages, respectively. Similar results were obtained at the Tioman Island, denoting that the AI during the training and testing periods did not show a drastic decrease. Hence, both the algorithms with input designs of SVM2 and GP2 were consistent and steady. Furthermore, no sudden substantial drop or rise in percentage can be observed because an increase in accuracy improvement that is within only 5% could be observed during the testing stage. This model input design is suitable for the long-term prediction of SL toward the end of this study because the correlation coefficients for both the models are capable of reaching ideal values with values of 0.75 and above in SVM2 and 0.73 and above in the GP2 model during training and testing, respectively.
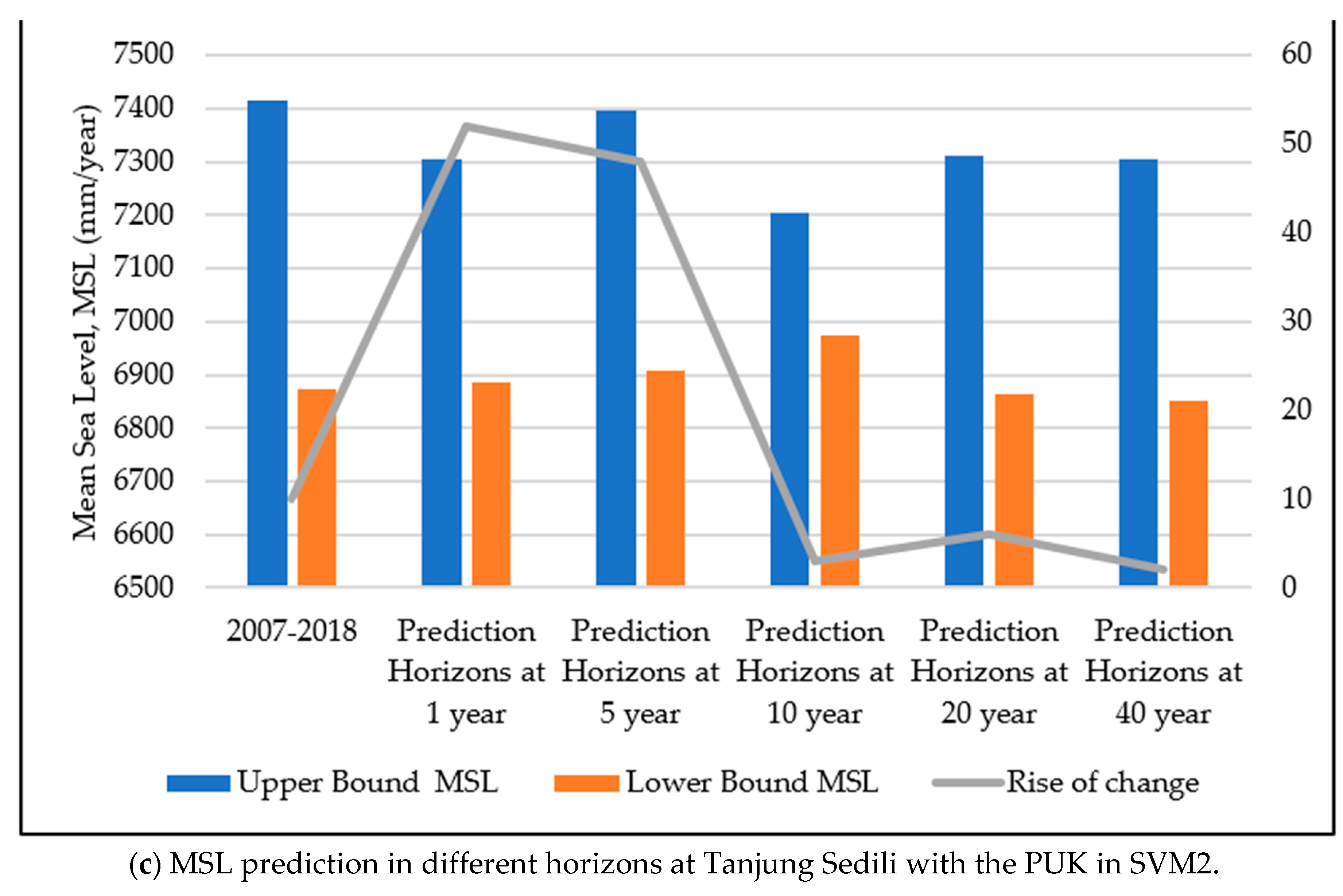
In accordance with
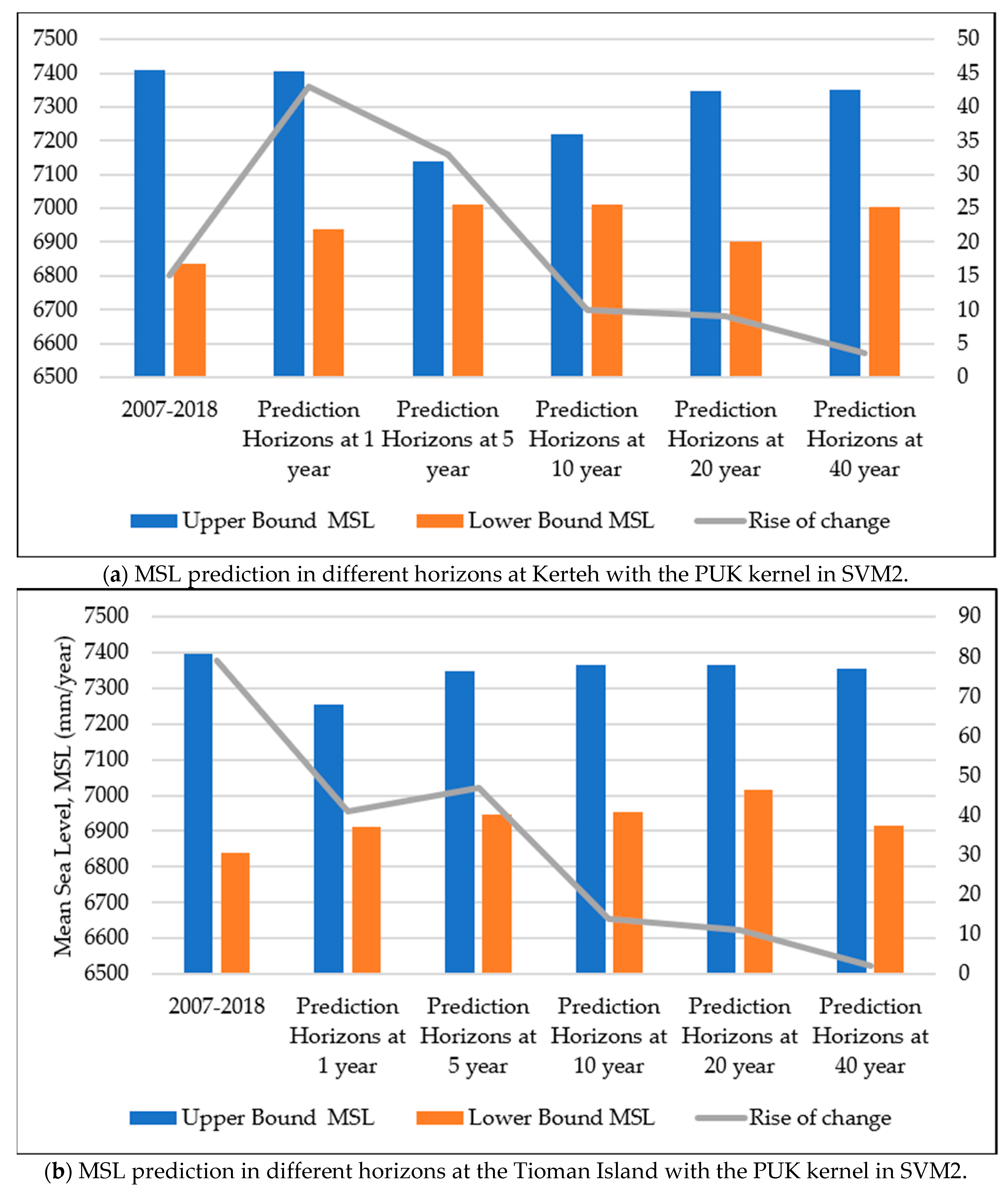
Figure 11, the predicted MSL from five different prediction horizons with an SVM2 input design at the study locations are presented with the upper and lower bounds of the predicted MSL.
Figure 11 depicts that the highest predicted MSL in the upper bound could be observed at a prediction horizon of 5 years at Tanjung Sedili with a value of 7396 mm. The second highest predicted MSL in the upper bound occurred at prediction horizons of 10 and 20 years at the Tioman Island with a value of 7396 mm. The lowest value in the upper bound of the predicted MSL was observed at Kerteh as 7350 mm at a predicted horizon of 40 years. However, the lowest value of the predicted MSL in the lower bound for all the study locations was between 6836 and 6852 mm. The minimum increase in the predicted MSL was 2.0 mm/year, whereas the maximum increase was 79.0 mm/year.
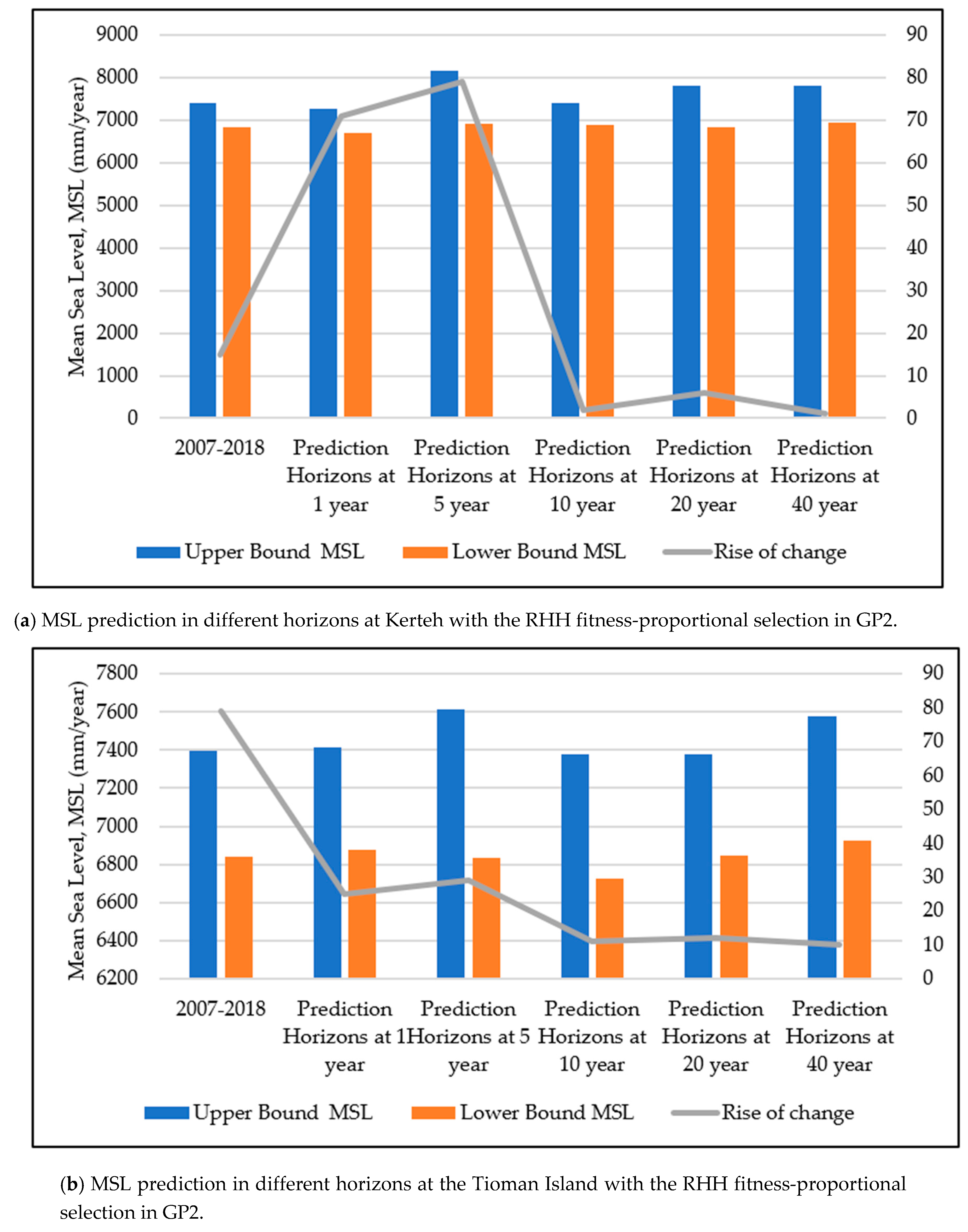
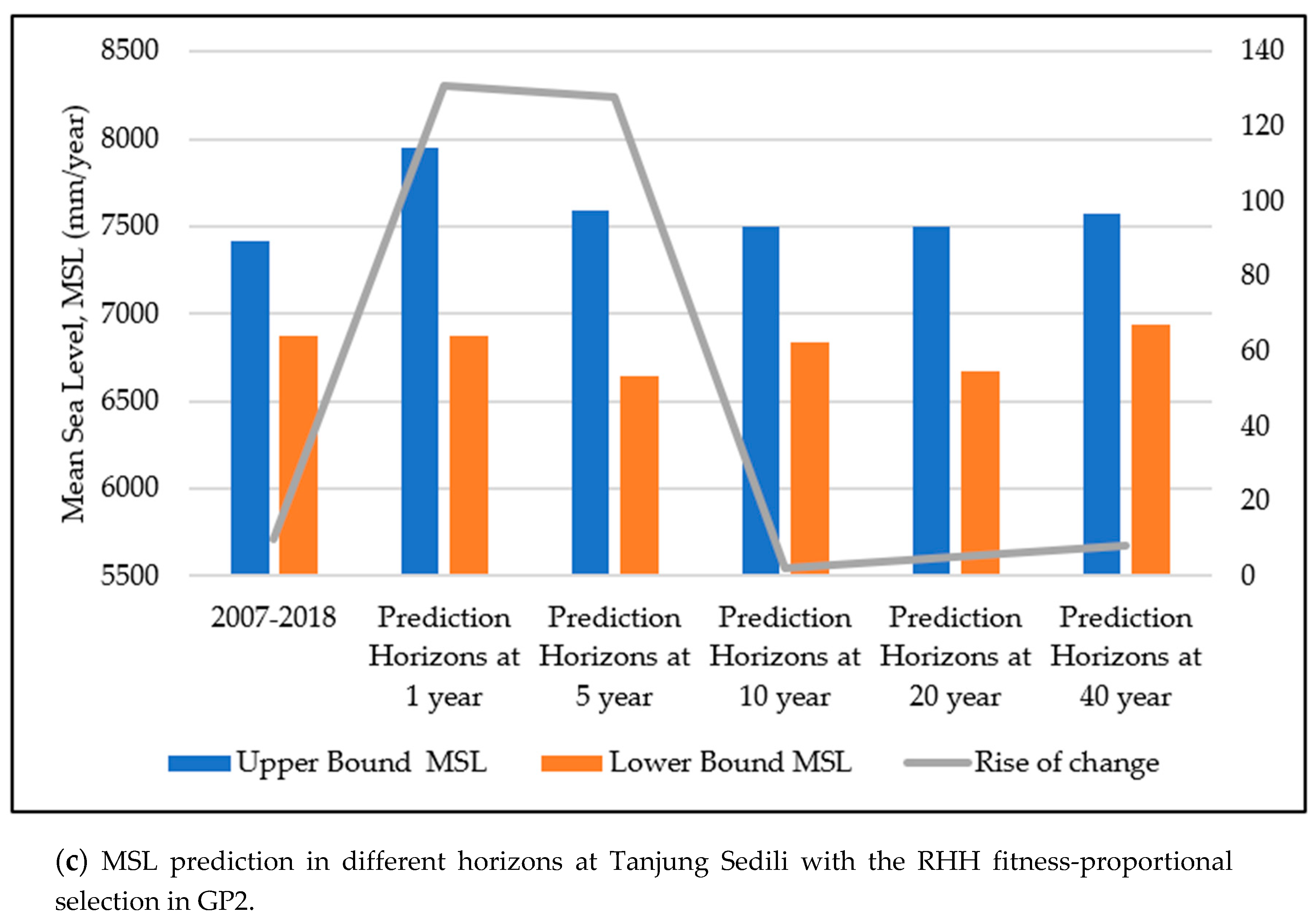
As illustrated in
Figure 12, the predicted MSL in five different prediction horizons with GP2 at the study locations are presented with the upper and lower bounds of the predicted MSL.
Figure 12 shows that the highest predicted MSL in the upper bound occurred at a prediction horizon of 1 year at Tanjung Sedili and was 7950 mm. The second highest predicted upper bound of the MSL occurred at a prediction horizon of 40 years at Kerteh and was 7805 mm. The lowest value in the upper bound of the predicted MSL was found at a prediction horizon of 5 years at the Tioman Island and was 7616 mm. However, the lowest value of the predicted MSL in the lower bound for all the study locations was between 6835 mm and 6840 mm. The minimum increase in the predicted MSL was 2.0 mm/year, whereas the maximum increase in the predicted MSL was 131.0 mm/year.
4. Conclusions
The capabilities of the SVM and GP models for MMSL prediction were examined herein based on the tide gauge data obtained from 2007 to 2017. SVM methods were compared with their functions, including the NP, RBF, and PUK kernels, to optimize the SVM model. The GP functions, namely RHH with rank selection and fitness-proportional selection, were also compared to assess the prediction accuracy of the GP model. The results indicated that the PUK in SVM2 and RHH with the fitness-proportional selection of the GP2 methods constitutes suitable techniques for analyzing the MMSL prediction and exhibited an effectively higher performance when compared with that exhibited by the remaining SVM and GP techniques. Different prediction horizons (i.e., 1, 5, 10, 20, and 40 years) were developed using SVM and GP to predict the MMSL. The overall results of the MMSL for SVM2 and GP2 at prediction horizons of 1 and 5 years showed an average maximum increment of 75 mm/year, whereas a prediction horizon of 10 years or more showed a decreasing sea level with a minimum average sea level of 10 mm/year at Kerteh, Tioman Island, and Tanjung Sedili. The outcome of MMSL at different prediction horizons implied that both the SVM2 and GP2 models exhibited stable performances. Therefore, both the proposed models are appropriate for predicting MMSL without bias or eliminating the hidden information in the time series. The results obtained from this study provide reliable prediction values with respect to the future increase in sea level at the identified coastal areas. Therefore, effective and economic planning pertaining to the safety and economics of the communities living along the coastal areas of Malaysia can be conducted by various state and federal authorities. Furthermore, the observations of this study could be a promising base for conducting further investigation on the proficiency of the SVM and GP models for sea level prediction in different time horizons. However, this study also exhibits limitations such as data availability. Therefore, conducting future research to perform further analysis on the sensitivity between each input variable with the associated output and identify the weight matrix could be a potential future research direction. Future studies may also focus on improving the proposed model by introducing other complex parameters as the model input, which has not been investigated in this study because of the limitation of the available data.
The modeling implementation process required a relatively long time to achieve the performance objective during training even though the proposed SVM and GP models showed an outstanding performance in case of MMSL prediction. In addition, the maximum relative error was still slightly high. Therefore, integrating the proposed methods (SVM and GP) with an advanced nature-inspired optimization algorithm that could accelerate the searching process for the global optimal solution is recommended to accelerate the training process. Furthermore, a model with an effective preprocessing method that could detect the inherent pattern of the raw data before feed, regardless of being an SVM or GP model, must be adapted to improve the overall prediction accuracy and reduce the maximum error.

 ,
, 

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}