
Abstract
Unanticipated failure of reinforced concrete structures due to corrosion of steel rebar embedded in concrete causes to increase the demand for finding methods to forecast the service life of concrete structures. In this field, the success of machine learning-based methods leads to the use of multi-gene genetic programming (MGGP) method for classifying the degree of corrosion destruction of steel in reinforced concrete in this paper. Despite the common application of MGGP that is the symbolic regression, in this research, MGGP was adapted to use in classification tasks. Accordingly, a large field database has been collected from different regions in the Persian Gulf for modeling of MGGP and neural networks. Comparing the results attained from the MGGP procedure with neural networks revealed that both methods have a good ability to predict the degree of steel corrosion damage for the data range of examined reinforced concrete. But, MGGP gives a particular mathematic equation to estimate the outcome by using the input variables. Moreover, this method can also implement sensitivity analysis simultaneously. The selected input variables by MGGP via the evolution process were the most relevant to the class corrosion whereas there was not any redundancy between them. It is in good agreement with results obtained from sensitivity analysis.
Similar content being viewed by others
1 Introduction
Steel corrosion in concrete is the most common reason for the degradation and poor durability of reinforced concrete (Angst 2018; Ben Seghier et al. 2021c). This destructive process consists of corrosion initiation and corrosion propagation stages (Ben Seghier et al. 2021b). The first stage is accompanied by ingress of carbon dioxide and carbonation of concrete cover (Nguyen et al. 2015) and increment of chloride content exceeds a critical value (Cao et al. 2019) or threshold level (Ann and Song 2007) in the surrounding concrete. Under these conditions, the concrete pH around reinforcement decreases then the protective film on the rebar surface breaks, and corrosion of steel rebar will begin. Before the corrosion initiation, the presence of a very thin and dense oxide film of iron on the surface of steel rebars is an excellent barrier to the corrosion of reinforcing bars which is stable in concrete with high pH (Berrocal et al. 2015; Al-majidi et al. 2019).
In the next stage, corrosion is occurred and corrosion products have been formed. The volume of this product (rust) is about 3 to 7 times greater than that of common steel volume and this causes high tensile stresses around the reinforcement and subsequently the concrete cover cracks (Tuutti 1982; Nguyen et al. 2015). The cracks increase access to destructive atmospheres such as oxygen, carbon dioxide and chlorine ions, thus staining, lamination, and degradation of the concrete cover occur and reducing the durability, safety, and useful service life of the Reinforced Concrete (RC) structures (Taffese and Sistonen 2017; Al-Akhras and Al-Mashraqi 2021).
Unforeseen RC failures not only cause economic losses due to repairs and increase energy consumption, but also affect the safety and quality of human life (Angst 2018). For example, the cost of maintenance and repair of RC structures in the United States is multibillion dollars per year and in Western Europe is 5 billion euros per year (Taffese and Sistonen 2017).
Therefore, the forecast of the useful service life and the design of the durable RC are major challenges to avoid the cost of premature damage and extend the service life of such structures. Corrosion in reinforced concrete (or penetration of chlorine ions and ingress of carbon dioxide into the concrete structure) is a complicated phenomenon involving many factors that are difficult to control (Ben Seghier et al. 2021c), so it cannot be predicted by conventional mathematical solutions or traditional computing methods.
Machine learning has been proven to be an efficient and reliable source for solving multiple engineering problems and it has many applications to solve nonlinear, multivariate and complex issues (Taffese and Sistonen 2017; Ben Seghier et al. 2021a). Artificial neural networks (ANNs) are one of the greatest commonly used methods of machine learning in the analysis and modeling of durability, service life prediction and corrosion problems of RC structures (Morcous and Lounis 2005; Parthiban et al. 2005; Ukrainczyk et al. 2007; Ukrainczyk and Ukrainczyk 2008; Topçu et al. 2009; Li et al. 2019; Roxas and Lejano 2019). Also, besides the fuzzy logic method (Anoop et al. 2002; Nehdi 2009; Sobhani and Ramezanianpour 2011), particle swarm optimization and support vector machine methods (Lv et al. 2020), genetic algorithm (Lee and Kim 2007) and a combination of these methods (Chatterjee et al. 2017) have been studied by several researchers for the behavior modeling of RC systems. For example; Parthiban and his coworkers (Parthiban et al. 2005) evaluated the performance of ANN in predicting the reinforcement potential of steel in reinforced concrete using experimental laboratory data and the back propagation neural network (BPNN) method. Ukrainczyk et al. (Ukrainczyk et al. 2007) suggested an ANN-based model for the prediction of the degree of corrosion destruction of reinforced concrete. Topçu et al. (Topçu et al. 2009) also used an ANN method to predict the corrosion current of reinforced concrete.
In spite of the advantages of the mentioned methods, they do not usually give a definite equation for calculating the output of the model. For example, the ANNs structure including the transfer function, the number of hidden layers and the number of neurons per layer must be known in advance (Gandomi and Alavi 2012a). Moreover, for a complicated database with various input parameters, accurate results may not be provided by ANN (Mai et al. 2020). This issue can be overcome by employing supervised machine learning procedures which give a particular mathematic equation to estimate the outcome such as genetic programming (GP) (Koza 1994). As an example of employing this approach to model the service life prediction of the tunnel structures, the implemented research by Gao et al. is considerable (Gao et al. 2019). multi-gene genetic programming (MGGP) is a modern technique of genetic programming that has been successfully employed in the analysis of various engineering issues (Gandomi and Alavi 2012a, b; Kaydani et al. 2014b; Garg and Lam 2015; Hoang et al. 2017). The benefits of this procedure are high learning ability andflexibility and the capability to deal with complex problems (Kaydani et al. 2014a). Furthermore, the accuracy of MGGP is more than a common GP and no researcher has been used from this approach to model the degree of corrosion damage in RC structures. Therefore, in this study, the new MGGP algorithm was used to formulate a mathematical relationship between the degree of damage in reinforced concrete structures located in the corrosive area of the Persian Gulf and input variables. The multi-gene genetic programming is also compared with an ANN model. Moreover, a large field database including various parameters was utilized, which have a significant impact on the corrosion process in the RC structures.
2 Methods and data collection
In this regard, 492 data were gathered from different regions located along in the Persian Gulf shown in Fig. 1. General information of each structure (point) including lifetime, concrete repair history, distance from the sea and elevation respect the sea level based on the technical reports and a global positioning system (GPS) were recorded. Also, distinctive properties were measured as: compression resistance of concrete and chloride penetration to concrete according to EN 13,791 standard and ASTM C114 standard, respectively; rebar diameter and concrete cover depth using an ultrasonic equipment; rebar potential which assessed by ASTM C876 standard and corrosion current density of rebar using pulse galvanostatic technique and ohmic resistance by a Randleʼs equivalent circuit. Accordingly, 12 parameters were considered as input variables for MGGP and neural network. The list of these parameters is shown in Table 1.

Different regions located along in the Persian Gulf (1–10) for data collection
Statistical information of the mentioned parameters in Table 1 including the mode, median, mean, minimum, maximum, standard deviation, and range of them is listed in Table 2. Furthermore, the histograms of the input parameters are illustrated in Fig. 2. From the statistical information in Table 2 and also the variable pattern of each parameter in the histograms of Fig. 2, it can be found that the problem is complicated.

Histograms of the input parameters: a Age b Concrete repairing history c Height above the sea level d Distance from sea e Concrete compressive strength f Rebar diameter g Concrete cover depth h Corrosion potential i Corrosion current density j Concrete electrical resistivity k Chloride ion concentration l Alkalinity of concrete
Since the range of input variables x1–x12 is not the same (i.e. we have different scales of data), the network considers large-scale variables more important than the small-scale ones. Therefore, it is necessary to normalize all the input variables to reduce the effect of scaling. All the input variable values are normalized within the interval (−1, 1). Table 3 shows the categorization criteria of reinforced concrete corrosion and the abundance of input data in the defined categories. According to Table 3, the data are categorized into four groups: the first group relates to the state that no corrosion has been observed in the evaluated structure. However, the fourth group relates to the structures that severe corrosion is occurred in them. The severity of corrosion in second and third groups is regarded between the aforementioned groups. By attention to the abundance of each categorize, it can be stated that a nearly comprehensive database is considered for the modeling.
2.1 The determination of output variables
To represent the four categories given in Table 3, four target variables are considered, i.e., t1, t2, t3, and t4 along with one-hot encoding. Accordingly, for representing the ith category, the variable ti is set to 1, and the others are set to 0; e.g. for indicating category 1 (the first class presented in this study) t1 = 1, t2 = 0, t3 = 0, and t4 = 0. Therefore, based on the above-given descriptions, an overall view of the dataset presented in this study is given in Table 4.
Categorization feature in ANNs is an effective tool that can be used for grouping a given set of correlated inputs. Feature categorization expressed whether the sample belongs to a particular class or not (Ukrainczyk et al. 2007; Ukrainczyk and Ukrainczyk 2008; Chatterjee et al. 2017).
Neural network architecture for pattern-classification is shown in Fig. 3. In this study, the corrosion category is designated as a distinct output. For this purpose, the input data are classified into four classes according to ASTM standard and visual observation (based on the intensity of corrosion).

Classification network architecture for 4 categories
The output variables for ANN and MGGP models are considered as y1, y2, y3, and y4 where t1, t2, t3, and t4 are the corresponding targets, respectively. Target variables t1, t2, t3, and t4 are the last four columns of the datasets, presented in this study.
3 Framework and methodology
3.1 Brief overview of GP and MGGP methods
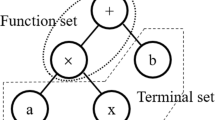
GP can generally be defined as a generated extension of the genetic algorithm (GA), though GP and GA have a significant difference. GP searches a program space (tree structures) rather than a data space. The algorithm initially generates a random population of individuals models based on the Darwinian principle to find the best/optimal solution. These individuals are hierarchically structured trees comprising terminal and function sets. The function set consists of mathematical functions, arithmetic symbols, Boolean operations, iterated functions and, conditional expressions. Terminator sets contain function relationships, variables, and constants (Koza 1994; Gandomi and Alavi 2012a). An example of a simple GP solution (i.e. a model tree) with output y and input variables such as a and b is shown in Fig. 4.

A form of a simple GP solution
The MGGP method is a new and vigorous type of GP that combines the capabilities of GP modeling with the ability to estimate the parameters of classic regression (Searson et al. 2010). Representation of standard GP is based on the expression of a single tree, while in the MGGP method, each individual derives from several genes that every tree can be considered as a gene, and the overall model is represented as a linear combination of weight of genes (Mohammadi Bayazidi et al. 2014).
The basic steps of the MGGP procedure are as follows; (a) First, a random primary population of computer programs (individuals) is generated, function sets and terminal sets are selected based on the problem. Then, the components of these two sets are randomly mingled to generate genes. The maximum depth of the tree and the number of genes must be specified by the user. (b) Second, evaluation of the initial population: determine the fitness function to evaluate the performance of every individual in the initial population (the fitness function is the objective function that must be optimized). (c) Third, generation of the new population: if termination condition such as the threshold error or the maximum number of generations of the model is not satisfied for an individual of the population, selection, crossover and mutation (the genetic operations) are applied to the models for the evolution of the new population. (d) Fourth, according to the minimum training error or the best-so-far solution, the best model is chosen (the repetitive process of creating a new population proceeds till the termination condition is attained) (Gandomi and Alavi 2012a; Garg and Lam 2015). Figure 5 shows the flowchart of the proposed MGGP approach. The dataset is randomly divided into two sub-categories, 80% of the data is used in the training process and 20% is used in the test to analyze the MGGP model. This Figure shows the evolutionary process of MGGP that is started by an initial population of chromosomes being randomly generated. In MGGP, each chromosome contains multiple genes and each gene is a mathematical expression (represented as a tree); in this research, 21 genes (trees) are considered to be in each chromosome. For adapting the MGGP to our four-class classification task, for the jth class, the output variable yj is considered. Then, for each output variable yj, 21 trees in each chromosome are combined by weights that are calculated using the least square estimator as follows:

Flowchart of proposed MGGP approach
The weights or linear coefficients (d0, d1, …, d21) are automatically computed from the training data set by applying the least square method for each multigene individual (Rahdari et al. 2016; Hoang et al. 2017). Figure 6 illustrates the symbolic model that predicts 4 output variables using input variables x1–x12 and 21 trees or genes.

The schematic structure of the symbolic model that is coded in each chromosome
For each individual, the fitness is calculated by the cross entropy that is described in the following. The fitness value for every individual is measured by Cross-Entropy (XE) given by:
where N is the number of train data, \({\text{y}}_{\text{j}}^{\text{i}}\) is the jth model output for the ith data sample and \({\text{t}}_{\text{j}}^{\text{i}}\) is the corresponding jth target.
3.2 Setting parameters of MGGP algorithm
In this study, a free open-source MATLAB toolbox called GPTIPS (Searson 2009) is utilized to accomplish MGGP. Various parameters that affected the model generalization ability of MGGP must be adjusted. The optimal parameter settings are listed in Table 5. The parameters are chosen according to a trial-and-error method. The victory of the MGGP algorithm ordinarily increments with enhancing the maximum permissible number of genes in an individual and maximum depth of the tree but the intricacy of the evolved function and running time increase (Kaydani et al. 2014b). Therefore, they must be set to optimal values (maximum number of genes = 21; maximum depth of tree = 4).
The remaining parameters of the MGGP model are selected as follows: the population size = 30; the maximum number of generations = 400; the tournament size = 8; cross over probability = 0.7; Mutation probability = 0.01. Tournament selection strategy with 8 tournament size is approved for choosing the parent genes. The next step is to choose the set of functions as well as the set of terminals, so use x1-x12 as terminals and “times, minus, plus, sqrt, square, tan, cot, exp, add3, mult3, pdiv, sin, cos, msig” as functions. “msig” is sigmoid function and for the variable u is defined as follows:
3.3 Artificial Neural Network framework
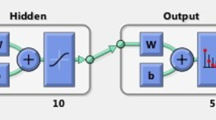
To estimate the best ANN model or to determine the optimum number of neurons in the hidden layer, model choice processes were utilized according to the K-fold cross-validation. In practice, this method often works well and is one of the most used methods in model selection. In K-fold CV, the total data are categorized into K folds (approximately equal size). Then (K-1) fold is assumed as a training data set and the residual fold is chosen as a test data set. The process is repeated K times and the test cross-entropy (XEi) is calculated at each time. Finally, the average of K tests XEi is a final error for each model. The model with the lowest average test cross-entropy (AXE) is selected as the best model (Shalev-Shwartz and Ben-David 2013). In this research, 10-Fold Cross Validation is used and a schematic of this method is shown in Fig. 7. The neural network containing 15 neurons in the hidden layer was selected as the best model. The ANN architecture is illustrated in Fig. 8 (12 input variables, 15 neurons in the hidden layer, and 4 output variables).

A schematic illustration of fivefold cross-validation

The best neural network structure obtained by tenfold CV
In order to train the best neural network, the dataset was randomly divided into two sets: 80% for training and 20% for test. The steps of the ANN approach are shown in Fig. 9. A common and popular back-propagation neural net (Perera et al. 2014; El et al. 2021) was employed as a topology of the ANN. It consists of two phases: (1) feedforward phase and (2) backpropagation phase and it has three main layers: an input layer, an intermediate hidden layer, and an output layer. Since the Levenberg–Marquardt training algorithm is often very fast and its prediction accuracy is high (Hadi 2003; Golafshani et al. 2012; Li 2015), so it was used for updating weights and biases value, although this algorithm needs more memory than others. The activation function of tan-sigmoid was used for both hidden and output layers. The maximum number of epochs for training is set as 1000 and the ANN model is trained until the maximum number of epochs is reached.

Flowchart of ANN approach
3.4 Comparing the structures of ANN and MGGP approaches
By comparing the proposed structures of ANN and MGGP, it can be apparently seen that the number of parameters for the ANN is bigger than those of MGGP. Since MGGP tunes only 22 × 4 = 88 parameters while the number of weights for ANN model are (12 × 15) + 15 = 195 weight parameters for the first layer and (15 × 4) + 4 = 64 parameters for the second layer (Totally 195 + 64 = 259). Another worth noting point is to compare and contrast the search mechanisms used for tuning the parameters and making the model structures. ANN backpropagation algorithm is employed as a gradient based method that uses the gradient of loss function for adjusting the aforementioned 259 parameters where this algorithm is a local search and it has the risk of trapping in local optima. In contrast, MGGP is an evolutionary algorithm and acts as a global search mechanism for finding the solutions through an iterative process of simulated evolution. Therefore, MGGP as a global search takes more computational efforts compared to the local search approaches like backpropagation but it is more likely that the global optimum of the loss function to be found by global search techniques like MGGP. As mentioned in Sect. 3.3, the structure of ANN model (number of layers and number of neurons in each layer) was obtained by employing cross-validation method, while MGGP determines the structure of model through the evolution process. MGGP automatically removes redundant and non-relevant variables to the outputs during iterations. Generally, it can be concluded that MGGP has the ability to escape from local optima in the search space in comparison with the ANN approach, while it is more computationally prohibitive in contrast to ANN. As the final important point, MGGP gives a mathematical formula as the final model where ANN is a black-box model.
4 Experiments and analysis
4.1 Performance metrics
Some commonly used metrics to evaluate the performance of the classification-type problems are accuracy, precision, recall, and F-measure (F1). The formulas of them can be seen in Eqs. (4)–(7) (Gandomi and Alavi 2011; Chatterjee et al. 2017), respectively.
where TP is true positive (The number of data accurately classified as positive), TN is true negative (The number of data accurately classified as negative), P is the total of samples correctly classified as positive, and samples inaccurately classified as negative (TP + FN), N is the total of TN and FP (The number of data that is incorrectly classified as positive). The relationship between these parameters constitutes the confusion matrix. F1 is the compatible mean of recall as well as accuracy and it is usually more useful than accuracy because it considers both precision and recall.
4.2 Numerical results and discussions
Figure 10 shows the changes in the best and mean fitness over the number of generations. As indicated, the fitness value reduced as the number of generations increased, and the best fitness was obtained in 400 generations (best fitness value = 1.9). It should be noted that the program did not produce better results for more generations.

The best and mean changes in fitness in terms of the number of generations
The vector TR is created by putting the obtained trees (tree1 to tree 21 given in Table 6) into a column vector as well as 1; TR = [1, tree1, tree2 … tree21]T. Also, considering the four column vectors β1 to β4 given in Table 7, the best anticipated equations obtained from the MGGP model to classify the degree of damage in reinforced concrete structures, reported as follows:
where the model outputs y1-y4 and input variables x1-x12 have been defined previously and tree 1 to tree 21 are the best trees obtained by MGGP, given in Table 6.
Table 8 illustrates the efficiency of derived models on training and test data for MGGP and ANN. By comparing the results, both models learned the influential correlation between input and output process parameters with a high accuracy. Although the value of performance measures given in Table 8 are close to each other for both ANN and MGGP, it is worth noting that the performance of MGGP on test data is better than ANN. The better performance of MGGP on test data shows its generalization ability compared to ANN. Therefore, the obtained results justify the superiority of MGGP in comparison with the ANN since it uses a global search mechanism and less parameters.
4.3 Sensitivity analysis
For determining the most essential parameter in anticipating the class of corrosion and therefore investigating the sensitivity analysis, one can use from Pearson correlation coefficient (PCC) method. It is a vigorous statistical estimate of the direction and strength of a linear dependency between two variables and also different indices can be evaluated by it in the science of materials (Chen et al. 2021). The PCC (r) regarding two variables X = {x1, x2, …, xn} and Y {y1, y2, …, yn}, defined as follows:
where \(\overline{x }\) denotes the mean of X and \(\overline{y }\) signifies the mean of Y, n is the sample size, and r is between −1 and 1. The two variables are directly related if the sign of r is positive, whereas they are inversely related if the sign of r is negative. The stronger the linear correction can be inferred provided that the r is close to + 1 or −1.
The PCC values between each pair of input variables x1 to x12 and class of corrosion are calculated and presented as a heat map in Fig. 11. As seen in the last row of Fig. 11, x6 and x7 are the least correlated variables to class corrosion. Concrete compressive strength (x5), corrosion current density (x9) and concrete electrical resistivity (x10) are the most remarkable variables to forecast the degree of corrosion damage. Corrosion current density is directly related to class corrosion, while concrete compressive strength and concrete electrical resistivity are inversely related to the output.

Pearsonsʼs correlation of inputs to output parameters
One of the most significant characters that control the acceleration of degradation of RC structures is corrosion current density (x9) (i.e. corrosion rate) and it inversely relates to concrete resistivity (x10). By decreasing the concrete resistivity, the corrosion current density augments. Moreover, the compressive strength of concrete (x5) is a noticeable mechanical property that is directly proportional to electrical resistivity for a similar concrete mixture design (Azarsa and Gupta 2017; Rodrigues et al. 2020).
Comparing the model given by MGGP with PCC analysis, the following facts have been concluded: Electrical resistivity of concrete (x10) is the most frequent parameter in the obtained equations of genes, while it is the most correlated feature with class corrosion (model output). Three features x6, x7 and x9 have a relatively strong negative correlation with x10 (according to Fig. 11) and thereby there is high redundancy between them, so they are omitted in the MGGP model (Fig. 6). However, there is a feeble redundancy between x1 and x11 with x10 (their correlation values are low) and consequently they are seen in the MGGP equations. These evidences justify the ability of MGGP as a powerful soft computing tool for modeling. As it can be seen from obtained equations of MGGP, the important input variables are considered in MGGP equations and redundant ones are automatically removed during its evolution process.
Furthermore, the electrical resistivity has been utilized in the progression of service life models due to the preparation of information about the electrochemical process (this process is completely related to corrosion of steel) and the widespread indicator of the microstructure of concrete (Andrade 2010; Mendes et al. 2018; Balestra et al. 2019).
5 Conclusions
This paper reports a new and effective technique, namely MGGP, for the formulation of the degree of damage in reinforced concrete structures located in the corrosive region of the Persian Gulf. This approach is based on genetic programming and it can be modeled the nonlinear complex behavior of the problems under study. The performance of MGGP is compared to ANN. To train these methods of machine learning, a data set containing 492 data has been collected. After running the program, results demonstrate that both models perform well with a high degree of accuracy. Although the MGGP method can generate nonlinear treatment without the necessity to predefine the structure, the ANN network structure must be identified in advance. Furthermore, MGGP gives a definite equation for calculating the output of the model. Therefore, the MGGP model can be used to evaluate design parameters in the planning and design phases of reinforced concrete structures for prediction service life and maintenance of them. The sensitivity analysis confirmed that MGGP has the ability to select the most relevant variables to class corrosion, while there is not any redundancy between them and consequently MGGP does not need any feature selection method for reducing the input variables as a preprocessing task.
Eventually, it is concluded that models like MGGP that employ a global search approach for constructing models will have better generalization performance on unseen data. Furthermore, the obtained models by symbolic regression approaches like MGGP (mathematical expressions) are more interpretable than black box models like ANN. MGGP has been usually used in regression problems and this study was one of the successful adaptations of this algorithm for a classification task in corrosion engineering. As a future work, this method can be used in gray box modeling of engineering problems, where we have an imprecise white box model of a process (e.g. governing differential equations). An imprecise white box model can be modified into an accurate one by adding some mathematical expressions being generated by symbolic regression methods through given data.
Code availability
The codes generated during the current study are available from the corresponding author on reasonable request.
Data availability and material
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Al-Akhras N, Al-Mashraqi M (2021) Repair of corroded self-compacted reinforced concrete columns loaded eccentrically using carbon fiber reinforced polymer. Case Stud Constr Mater 14:e00476. https://doi.org/10.1016/j.cscm.2020.e00476
Al-majidi MH, Lampropoulos AP, Cundy AB et al (2019) Flexural performance of reinforced concrete beams strengthened with fi bre reinforced geopolymer concrete under accelerated corrosion. Structures 19:394–410. https://doi.org/10.1016/j.istruc.2019.02.005
Andrade C (2010) Types of models of service life of reinforcement: the case of the resistivity. In: Concrete Research Letters, pp. 73–80
Angst UM (2018) Challenges and opportunities in corrosion of steel in concrete. Mater Struct 51:4. https://doi.org/10.1617/s11527-017-1131-6
Ann KY, Song H (2007) Chloride threshold level for corrosion of steel in concrete. Corros Sci 49:4113–4133. https://doi.org/10.1016/j.corsci.2007.05.007
Anoop MB, Rao KB, Rao TVSRA (2002) Application of fuzzy sets for estimating service life of reinforced concrete structural members in corrosive environments. Eng Struct 24:1229–1242. https://doi.org/10.1016/S0141-0296(02)00060-3
Azarsa P, Gupta R (2017) Electrical resistivity of concrete for durability evaluation: a review. Adv Mater Sci Eng 2017:8453095. https://doi.org/10.1155/2017/8453095
Balestra CET, Nakano AY, Savaris G, Medeiros-Junior RA (2019) Reinforcement corrosion risk of marine concrete structures evaluated through electrical resistivity: proposal of parameters based on field structures. Ocean Eng 187:106167. https://doi.org/10.1016/j.oceaneng.2019.106167
Ben Seghier MEA, Corriea JAFO, Jafari-Asl J et al (2021a) On the modeling of the annual corrosion rate in main cables of suspension bridges using combined soft computing model and a novel nature-inspired algorithm. Neural Comput Appl 33:15969–15985. https://doi.org/10.1007/s00521-021-06199-w
Ben Seghier MEA, Keshtegar B, Mahmoud H (2021b) Time-dependent reliability analysis of reinforced concrete brittle fracture. Materials (Basel) 14:1820. https://doi.org/10.3390/ma14081820
Ben Seghier MEA, Ouaer H, Ghriga MA et al (2021c) Hybrid soft computational approaches for modeling the maximum ultimate bond strength between the corroded steel reinforcement and surrounding concrete. Neural Comput Appl 33:6905–6920. https://doi.org/10.1007/s00521-020-05466-6
Berrocal CG, Lundgren K, Löfgren I (2015) Corrosion of steel bars embedded in fibre reinforced concrete under chloride attack: State of the art. Cem Concr Res 80:69–85. https://doi.org/10.1016/j.cemconres.2015.10.006
Cao Y, Gehlen C, Angst U et al (2019) Critical chloride content in reinforced concrete—an updated review considering Chinese experience. Cem Concr Res 117:58–68. https://doi.org/10.1016/j.cemconres.2018.11.020
Chatterjee S, Sarkar S, Hore S et al (2017) Structural failure classification for reinforced concrete buildings using trained neural network based multi-objective genetic algorithm. Struct Eng Mech 63:429–438. https://doi.org/10.12989/sem.2017.63.4.429
Chen H, Cui H, He Z et al (2021) Influence of chloride deposition rate on rust layer protectiveness and corrosion severity of mild steel in tropical coastal atmosphere. Mater Chem Phys 259:123971. https://doi.org/10.1016/j.matchemphys.2020.123971
El M, Ben A, Keshtegar B et al (2021) Advanced intelligence frameworks for predicting maximum pitting corrosion depth in oil and gas pipelines. Process Saf Environ Prot 147:818–833. https://doi.org/10.1016/j.psep.2021.01.008
Gandomi A, Alavi A (2011) Multi-stage genetic programming: a new strategy to nonlinear system modeling. Inf Sci (NY) 181:5227–5239. https://doi.org/10.1016/j.ins.2011.07.026
Gandomi AH, Alavi AH (2012a) A new multi-gene genetic programming approach to nonlinear system modeling. Part I: Materials and structural engineering problems. Neural Comput Appl 21:171–187. https://doi.org/10.1007/s00521-011-0734-z
Gandomi AH, Alavi AH (2012b) A new multi-gene genetic programming approach to non-linear system modeling. Part II: geotechnical and earthquake engineering problems. Neural Comput Appl 21:189–201. https://doi.org/10.1007/s00521-011-0735-y
Gao W, Chen X, Chen D (2019) Genetic programming approach for predicting service life of tunnel structures subject to chloride-induced corrosion. J Adv Res 20:141–152. https://doi.org/10.1016/j.jare.2019.07.001
Garg A, Lam JSL (2015) Improving environmental sustainability by formulation of generalized power consumption models using an ensemble based multi-gene genetic programming approach. J Clean Prod 102:246–263. https://doi.org/10.1016/j.jclepro.2015.04.068
Golafshani EM, Rahai A, Sebt MH, Akbarpour H (2012) Prediction of bond strength of spliced steel bars in concrete using artificial neural network and fuzzy logic. Constr Build Mater 36:411–418. https://doi.org/10.1016/j.conbuildmat.2012.04.046
Hadi MNS (2003) Neural networks applications in concrete structures. Comput Struct 81:373–381. https://doi.org/10.1016/S0045-7949(02)00451-0
Hoang ND, Chen CT, Liao KW (2017) Prediction of chloride diffusion in cement mortar using multi-gene genetic programming and multivariate adaptive regression splines. Meas J Int Meas Confed 112:141–149. https://doi.org/10.1016/j.measurement.2017.08.031
Kaydani H, Mohebbi A, Eftekhari M (2014a) Permeability estimation in heterogeneous oil reservoirs by multi-gene genetic programming algorithm. J Pet Sci Eng 123:201–206. https://doi.org/10.1016/j.petrol.2014.07.035
Kaydani H, Najafzadeh M, Hajizadeh A (2014b) A new correlation for calculating carbon dioxide minimum miscibility pressure based on multi-gene genetic programming. J Nat Gas Sci Eng 21:625–630. https://doi.org/10.1016/j.jngse.2014.09.013
Koza JR (1994) Genetic programming as a means for programming computers by natural selection. Stat Comput 4:87–112. https://doi.org/10.1007/BF00175355
Lee CK, Kim SK (2007) GA-based algorithm for selecting optimal repair and rehabilitation methods for reinforced concrete (RC) bridge decks. Autom Constr 16:153–164. https://doi.org/10.1016/j.autcon.2006.03.001
Li X, Khademi F, Liu Y et al (2019) Evaluation of data-driven models for predicting the service life of concrete sewer pipes subjected to corrosion. J Environ Manage 234:431–439. https://doi.org/10.1016/j.jenvman.2018.12.098
Li GD (2015) Corrosion evaluation model of reinforcement in concrete based on ANN. 8th Int Conf Intell Comput Technol Autom Corros, pp. 341-344 doi: https://doi.org/10.1109/ICICTA.2015.92
Lv Y, Wang J, Wang J et al (2020) Steel corrosion prediction based on support vector machines. Chaos Solitons Fractals 136:1–10. https://doi.org/10.1016/j.chaos.2020.109807
Mai SH, Ben Seghier MEA, Nguyen PL et al (2020) A hybrid model for predicting the axial compression capacity of square concrete-filled steel tubular columns. Eng Comput. https://doi.org/10.1007/s00366-020-01104-w
Mendes SES, Oliveira RLN, Cremonez C et al (2018) Electrical resistivity as a durability parameter for concrete design: Experimental data versus estimation by mathematical model. Constr Build Mater 192:610–620. https://doi.org/10.1016/j.conbuildmat.2018.10.145
Mohammadi Bayazidi A, Wang GG, Bolandi H et al (2014) Multigene genetic programming for estimation of elastic modulus of concrete. Math Probl Eng 2014:12–15. https://doi.org/10.1155/2014/474289
Morcous G, Lounis Z (2005) Prediction of onset of corrosion in concrete bridge decks using neural networks and case-based reasoning. Comput Civ Infrastruct Eng 20:108–117. https://doi.org/10.1111/j.1467-8667.2005.00380.x
Nehdi ML (2009) Fuzzy logic approach for estimating durability of concrete. Proc Inst Civ Eng 162:133–138. https://doi.org/10.1680/coma.2009.162
Nguyen TTH, Bary B, De Larrard T (2015) Coupled carbonation-rust formation-damage modeling and simulation of steel corrosion in 3D mesoscale reinforced concrete. Cem Concr Res 74:95–107. https://doi.org/10.1016/j.cemconres.2015.04.008
Parthiban T, Ravi R, Parthiban GT et al (2005) Neural network analysis for corrosion of steel in concrete. Corros Sci 47:1625–1642. https://doi.org/10.1016/j.corsci.2004.08.011
Perera R, Tarazona D, Ruiz A, Martín A (2014) Application of artificial intelligence techniques to predict the performance of RC beams shear strengthened with NSM FRP rods. Formulation of design equations. Compos PART B 66:162–173. https://doi.org/10.1016/j.compositesb.2014.05.001
Rahdari F, Eftekhari M, Mousavi R (2016) A two-level multi-gene genetic programming model for speech quality prediction in Voice over Internet Protocol systems. Comput Electr Eng 49:9–24. https://doi.org/10.1016/j.compeleceng.2015.10.008
Rodrigues R, Gaboreau S, Gance J et al (2020) Reinforced concrete structures : A review of corrosion mechanisms and advances in electrical methods for corrosion monitoring. Constr Build Mater 269:121240. https://doi.org/10.1016/j.conbuildmat.2020.121240
Roxas CLC, Lejano BA (2019) An artificial neural network model for the corrosion current density of steel in mortar mixed with seawater. Int J GEOMATE 16:79–84. https://doi.org/10.21660/2019.56.4585
Searson DP, Leahy DE, Willis MJ (2010) GPTIPS: An open source genetic programming toolbox for multigene symbolic regression. Proc Int MultiConference Eng Comput Sci 1:77–80
Searson D (2009) Genetic programming and symbolic regression for MATLAB. http://gptips.sourceforge.net
Shalev-Shwartz S, Ben-David S (2013) Understanding machine learning: From theory to algorithms
Sobhani J, Ramezanianpour AA (2011) Service life of the reinforced concrete bridge deck in corrosive environments: A soft computing system. Appl Soft Comput J 11:3333–3346. https://doi.org/10.1016/j.asoc.2011.01.004
Taffese WZ, Sistonen E (2017) Machine learning for durability and service-life assessment of reinforced concrete structures: Recent advances and future directions. Autom Constr 77:1–14. https://doi.org/10.1016/j.autcon.2017.01.016
Topçu IB, Boǧa AR, Hocaoǧlu FO (2009) Modeling corrosion currents of reinforced concrete using ANN. Autom Constr 18:145–152. https://doi.org/10.1016/j.autcon.2008.07.004
Tuutti K (1982) Corrosion of steel in concrete. Cement-och betonginst
Ukrainczyk N, Ukrainczyk V (2008) A neural network method for analysing concrete durability. Mag Concr Res 9831:475–486. https://doi.org/10.1680/macr.2007.00016
Ukrainczyk N, Pecur IB, Bolf N (2007) Evaluating rebar corrosion damage in RC structures exposed to marine environment using neural network. Civ Eng Environ Syst 24:15–32. https://doi.org/10.1080/10286600601024749
Funding
This project was supported by Hormozgan Regional Electric Company (HREC) and Niroo Research Institute (NRI), info@hrec.co.ir and info@nri.ac.ir.
Author information
Authors and Affiliations
Contributions
ZR: Conceptualization, methodology, software; ME: conceptualization, methodology, software, supervision; MG: project administration; ME: conceptualization, methodology, software, supervision; HB: conceptualization, investigation, data curation.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Consent for publication
It is consented for publication.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Rajabi, Z., Eftekhari, M., Ghorbani, M. et al. Prediction of the degree of steel corrosion damage in reinforced concrete using field-based data by multi-gene genetic programming approach. Soft Comput 26, 9481–9496 (2022). https://doi.org/10.1007/s00500-021-06704-2
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s00500-021-06704-2